Effective climate management strategies – those that prepare business or an organisation for future climate regimes – most often need plausible series of data, at the daily timescale, from which to devise adequate coping strategies. One option is to take daily series of weather directly from global numerical models that simulate future climate.

A second option is to blend characteristics of the projected climate with real-world, observed information in order to synthesize a series of daily data that has many of the statistical properties from the real world, but adjusted in some form to reflect the future climate. This second option, in itself, has a number of sub-options as to how exactly the unification of real-world characteristics and the projected climate change can be achieved and it has been the subject of focussed research to identify the most effective techniques given the end use of the data. This is an important topic within climate services, where the trade offs between the methods must be carefully assessed and acknowledged when applying the data to quantify your climate risks.
One popular technique in climate science, for the generation of rainfall data in particular, is to adopt a mathematical technique known as a Markov chain, named after the Russian mathematician Andre Markov. The technique is a powerful tool for representing systems with two states — wet and dry in this case — and it can be designed by ‘learning’ from a series of real-world observations for the desired location and then run for a future climate to generate a sequence of dry or wet days. Markov Chains are popular since they are able to embody a memory of the system you are trying to represent. For example, a Chain can be devised to produce a series of data indicating whether each day is dry or wet, whilst accounting for whether the previous 2, 3, or 4 days have been wet or dry themselves. The parameters that control the probability of the day’s state (and how much emphasis to place of each of the historical day’s state) are derived from the real-world observation series you feed the chain (this is the ‘learning’).
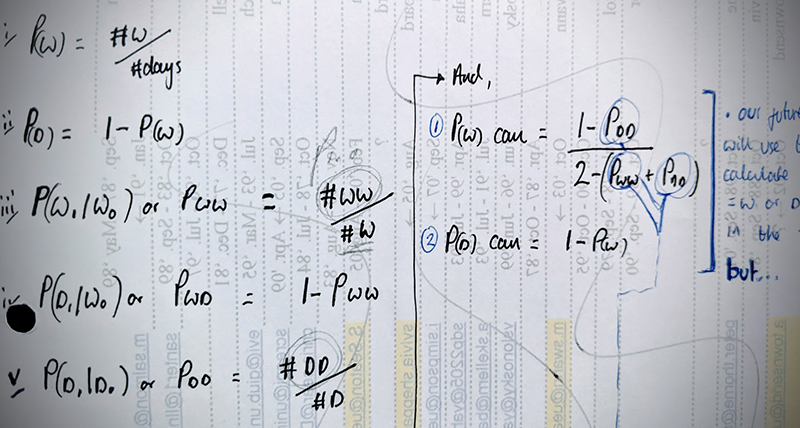
Having established a series of wet or dry days, a second mathematical module, not strictly part of the Markov process, will provide rainfall amounts – by randomly choosing a value from a population of possible amounts – and then the whole series is scaled (either inflated or deflated) to match the future climate provided by the numerical climate model (e.g. a monthly total). The bottom line advantage of this technique is that the day-to-day series of rain or no rain can adhere to statistical properties of the real world, rather than the numerical climate model, which may have implicit differences to the real world, especially when it comes to simulating daily processes.
Until recently, very little attention has been given to how long the ‘memory’ of the Markov Chain should be whilst synthesizing data for different climatic zones. Should the Markov chain know about just 2 days previous conditions to decide whether or not today is wet? Or 3? And, which number is best for applications in Seattle (a pretty wet climate) as opposed to Los Angeles (dry)?
In the IJOC paper, Sarah built Markov Chains using over 44 000 rainfall observation series covering the globe to see which memory length (or ‘order’) was optimal for recreating the observed rainfall characteristics at each location.

Perhaps surprisingly, for most cases, a Markov Chain with just one day’s memory appears to be the most optimal for recreating the actual observed sequence of wet or dry days. This is intriguing, although likely a reflection of the time-frame of many weather systems that result in rain.
The exception to this finding occurs in the tropics, where zeroth (i.e. no memory what-so-ever) and third-order (three day’s memory) chains perform well and, in the case of re-creating lengths of dry spells, better than first order Chains.
These findings may sound trivial in a sense, since they are an aspect of climate science that remains hidden to many people away from the front face of research and statistical consultancy. But they are very important inputs in order to update existing mathematical tools and to offer further flexibility, depending on the geographical location of the project in question.
– Craig Wallace, EarthSystemData